Javasoljuk, ne futtassa ezt az applikációt, mert a futásidő
akár több óra is lehet. Helyette megmutatunk néhány előre lefuttatott példát
itt:
'HALL' szóra való keresésénél a futásidő (nyiván
véletlenszerűen) 1 perc 36 mp lett, az
összes karaktersorozat száma: 19445, az értelmes szavak száma: 236 - ezek:
PATA, AVAT,
EPED, IHOL, FÖNT, GYÜN, IGEN, KACS, NÉMA, BŐSZ, TAXA, NESZ, VÉSZ, GÁLA, ZACI, ÁPOL,
EGÉR, ENNY, ÜLET, DŰLŐ, FUGA, SZÁR, GUGA, BUJA, DARU, RÉSZ, PISI, PÉTI, ÖRÜL, LÉHA,
FINN, BOJT, KLÓR, GYŰR, RÉSZ, VISZ, DARU, PEDZ, UGAT, KRAL, ELVI, IDŐS, TUJA, SAFE,
ÜTET, HUJJ, ÉRIK, SZÉT, FIKA, CETT, SOHA, ÓNOS, ÍVEL, TETU, NERC, FÜST, VÁRÓ, PRÉS,
PÁKA, ÁPOL, EVET, ASZÚ, MÓDI, ÉLÉS, RÁNG, ZÚGÓ, EZER, SODÓ, FACH, FALÓ, NYÍL, PERC,
PONT, ÉTEL, ETET, KUKK, BARI, STÍL, CIGI, ZÁRT, ÉTER, NYÍR, INGÓ, SOTU, SOLO, ÖLTŐ,
PAFF, KORC, PERC, PINT, FUTÓ, KÖRÉ, HALÓ, RING, HŰLT, UJJÉ, DONG, ZUHÉ, BUJT, ÜSZŐ,
ÜTÉS, HAJÓ, BÚGÓ, MÁMA, MÁRC, TIPP, ÖNTŐ, KÓLÓ, REND, AMAZ, ELUN, NYÍL, CIKK, MÓLÓ,
ŐRÖL, NONÁ, SODÓ, HOGY, TŰZŐ, ÉGÉS, GÓRÉ, UGAT, ÜLET, ÖCSI, MORC, MELY, OMOL, AVAR,
RÜGY, TETU, EJHA, ÍZÍK, FÜST, GYŰR, TELT, MINŐ, MINK, BÉRC, SZER, SATU, PICE, HAMU,
BUJT, FÚGA, RÖMI, ÜRÜL, LERÍ, ÜDÜL, EMEZ, GYÍK, SETE, SÍRI, MENT, NONO, HAMU, EMEZ,
FÜST, HUJJ, RÓKA, VEND, HAHÓ, BENT, NYÍR, SZEN, REDŐ, LÉGY, NOHA, MINŐ, GEBE, CISZ,
HUJA, TERC, RÖMI, SZÁK, ÖRÜL, FOJT, NÉGY, LELŐ, BUSZ, ÜGET, ÚTŐR, SOLO, ÉGÉS, VEND,
ŐRÖL, ITAT, GYŐZ, EVEZ, SATU, ÚJJÁ, MOLL, ÉLET, PONK, REVÜ, MEGÉ, ÉVAD, NYÚL, BOJT,
GYÜN, KORC, ÜLET, SZOP, TERC, UJJÉ, ÍZES, NYÍR, GYÚL, ÍVEL, ÍREZ, SÉTA, ÜLET, EPER,
TAHÓ, AVAT, PENG, ZAKÓ, KÜSZ, CSÍP, ÜRÜL, RÁCS, TAXA, BUJT, PECH, SARU, FALÓ, ÜGET,
EVÉS, ELŐL, CSÉK, VETŐ, DUGA, IDÉN, LENT, LAKK, UNKA, HALL.
Ugyanerre a szóra való keresésénél a futásidő 15 perc 29
mp lett, az
összes karaktersorozat száma: 128 947, az értelmes szavak száma: 1 679 - ezek:
FOJT, OKUL, RÁNG, UGAR, SZÖG, LÁTÓ, BONT, BIRS, MINŐ, SZÚR, KIES, ZÚGÓ, BONT,
FÚRÓ, SÚLY, ÁNGY, KOPÓ, ÍJAS, ÜDÍT, KONG, JÁRT, OLÁH, FIÓK, KORA, ELÜT, ÖLÉS, KÜNN,
KONG, TEVŐ, ELŰZ, FŰZŐ, NÁCI, HIBA, RAJZ, KÁPA, PERC, REGE, PULT, HARC, BANK, SÜTŐ,
IKER, KESE, KÓRÓ, FEST, PÁNT, RAGU, KÜLD, FAGY, PONT, GYŐZ, VELE, TŐGY, RÁMA, ESTE,
BUDI, PÓRÉ, HARS, AZÚR, PEDZ, ÖNTŐ, FÁJÓ, TELT, UKÁZ, TÉMA, ECHÓ, BUTA, TOSZ, RÓKA,
HAJÓ, IDEI, DŰNE, FENN, MORE, UGAT, ANNO, NYÁK, HEGY, APAI, ÓRAI, CIKK, BENN, LERÍ,
MORE, ERES, NEJE, REND, FŐZŐ, NYÁL, HAMM, LÁTÓ, SZÁL, CSÉK, FEDD, KIFŐ, MEJJ, RÓTT,
SÓLÉ, ZSÁK, HÁNY, HOHÓ, LENG, GYÁM, ELUN, PIKK, NAPA, BŐGŐ, POLC, KARI, BÖGY, FRÉZ,
ELÉL, FŐZŐ, CSÉK, KÉVE, DIDI, NÁSZ, PANG, PÓRI, ÖNTŐ, IGÉZ, MART, GYÁR, FIKA, SZÖK,
FŰZŐ, ÖBÖL, FIÓK, GANG, IVÁS, PÓRI, HUNY, TOJÓ, DONG, MARI, RÜGY, PARI, KOMI, RÁZÓ,
EDZŐ, RÓKA, PACI, KÜNN, BITÓ, FOGY, BÁBU, LEJT, BŐGŐ, APUS, ÚTŐR, VESZ, DUGÓ, SRÉT,
DÁKÓ, GANG, RÁCS, ÁCSI, KÖLL, ECHÓ, AISZ, HUTA, KÜNN, EHUN, ALUL, KÜNT, FENE, LENN,
POPÓ, KINN, ROST, KOSZ, FACH, MARÓ, FÚGA, ÓZON, JUTA, LÓRÉ, DŐRE, OJJÉ, IMÁD, ÖRÜL,
VÉTŐ, ROGY, ERES, HATÓ, ÁNGY, ÖRÜL, SÜTŐ, ÚJÉV, AKUT, SŐRE, DÓKA, CSŐR, NONÁ, SVÉD,
APÓS, KÖZÉ, TŰZŐ, IVAR, ÁTÉG, VESZ, TOJÓ, NAPI, TOTÓ, NÉHA, KULI, LÓGÓ, ELIT, ÉVES,
TEVŐ, PÓRÉ, KECS, ÖNZŐ, BÜTÜ, KÉRŐ, BUKÓ, PFUJ, ÓDON, BIBE, ÖVÉK, ÚJON, RIGÓ, ELÜT,
HALÓ, MARÓ, HADI, PÓKA, JÓGA, AJTÓ, INGA, GYŰR, BÍRÓ, EMEL, JÁRÓ, MOND, RÁTA, ÁRAD,
ELÍR, DŐRE, ÓRAI, LÓFŐ, ÁRVA, SVÉD, BUKÓ, SING, ROGY, MÉCS, DANA, MÉRT, DONG, KÓTA,
ÓZON, KEDD, AZAZ, PÓKA, BUTI, SZOL, RIZS, KAKA, ÉRTE, AJAK, IRAM, APRÓ, EMEL, RANG,
ÖRÜL, TŐGY, ELIT, SEJK, TOSZ, LEJT, ÓZON, MAGA, ÁPOL, GŐTE, EGÉR, PÁPA, HELY, ÖZÖN,
TELI, ÓSDI, PETE, PÖNG, VEVŐ, FENT, MÁMA, CIKK, BELE, MOHA, KÜNT, BOLY, RÓTT, IMÁM,
CSÉK, BUKÉ, FAIR, NÉZŐ, ÜTET, IPAR, RAGU, AGÁR, PIAC, BÚGÓ, ACÉL, OKÁD, MÁMA, FONT,
DARU, SZÁZ, ÉGÉS, UTÓD, IKES, ÁPOL, MENT, BOLY, NYÁK, VISZ, ÁLOK, FŐTT, CIGI, SEJK,
ALIG, LŐRE, SING, LENN, HOKI, HINT, TERÜ, TÚLI, SÚGÓ, REDŐ, TRÓN, VESZ, KORA, AKAR,
BÁNT, ÓMEN, NYŰG, MÉRT, FOGÓ, MORC, PISI, RIAN, BRIT, LENG, SZÖG, PANG, DUGA, FUTÓ,
VOLT, HUJA, TEVE, EMEL, SZOL, ÍZÉS, SZŐR, BÜTÜ, KOPÓ, NYÁK, ÜDÜL, ÍVIK, MÓDI, CSŐR,
FOJT, HÚGY, LŐRE, FOGY, AKUT, SZOL, VARR, NÉZŐ, ÜHÜM, RESÓ, IGEN, ÍTÉL, TŰZŐ, ZSÚR,
KINŐ, EGÁL, FACH, NYÁR, NYŰG, LÓRÉ, PÖCS, LENG, GYŰR, KIRÓ, FOTÓ, SZŐR, FORR, TŰZŐ,
KÚRA, ELUN, ÁHÍT, BUTA, RAGU, BOJT, ZAKÓ, SOKK, HŰTŐ, SZŐR, IVÁS, CINK, MÓDI, KINŐ,
CULA, SZÖG, ÉVES, FEDD, EHUN, KONG, PIKA, ÜLÉS, ÍZÉS, ÉKÍT, FEST, KÓRÓ, HELY, ESTE,
CÁPA, KÉVE, ESTI, HUKK, ÉKEL, SÉRT, VAGY, BOJT, SEGG, RÚZS, SÚJT, NYŰG, ECHÓ, EMEL,
SZOL, BONG, IDŐS, GYŐZ, SOLO, FŐTT, UTÓD, TEVE, LENN, LÁTÓ, OMOL, MENY, LAPU, MÉRT,
IRAT, ÁHÍT, ERŐS, BUJT, SZŰZ, SEGG, DELI, PRÉM, TÜTÜ, FÓKA, PÉNZ, FÚRT, GITT, CÁRI,
RING, AKOL, KIFŐ, SVÁB, LETT, STÉG, BENN, MEGY, FŐFŐ, BIKK, MENŐ, EBÉD, IGÉZ, ZÚGÓ,
TŐGY, TŐKE, DALI, PIKK, SZÍV, SZŐR, PÁPÁ, SŐRE, MOND, TŐKE, INGÓ, MÁMA, DONG, NONO,
SZÁL, LÉHA, ÉLÉS, TŐKE, ÜRÍT, TRIÓ, SZÓR, GYŰR, SRÁC, LAKK, ÓNAS, HUNY, TŰZŐ, SÍRÍ,
SIKK, TÚRA, BRIT, AZON, TŐGY, TEVŐ, REGE, BANK, GISZ, HANT, GITT, FÚRT, VONT, JUTA,
PART, KACS, PISI, BOLY, OKOL, PAKK, APRÓ, SZÁM, PÁKA, ÍZÍK, CSÚZ, VÁJÓ, JAVA, SÜTŐ,
ÖCSI, TÚSZ, RÁNG, RAJZ, CSÍP, PICI, RÓTT, HÁTI, BÚGÓ, FACH, KÁRÓ, TÚRÓ, FEDŐ, PÁRA,
INTŐ, VERT, TOJÓ, IGÉZ, ÉKEL, ÍREZ, RÉPA, HASI, BŐGŐ, SAJT, ÍREL, PÁPA, HIVŐ, SZÖK,
HONN, RÉSZ, AJAK, JUTA, SZŰZ, EHUN, RANG, FÁMA, VÉTŐ, KÓRÓ, VARR, EVEZ, UGAR, CSÍZ,
CSÓK, TÚRÓ, BONG, PAKK, HEHE, IVAR, TŐGY, TÉKA, SZÉK, VÁJÓ, RIMA, ÓZON, ZSÚR, MÁMA,
HŰHÓ, ÉPÍT, SOKÁ, FASÉ, REDŐ, ACÉL, ÍTÉL, BÁBU, VÉRT, SZÖK, ZSÍR, AJKÚ, ŐRIZ, ZÚGÓ,
FAKÓ, TÜLL, CSAK, ZAGY, DARA, JUTA, ÖREG, BENT, ZÚGÓ, KOSZ, AKTA, SZŐR, AZON, VERS,
KAPA, FELE, ÁMEN, SÜLY, SZÉR, IKES, ÍVÁS, PISI, MUST, ÁDÁZ, ZÚGÓ, ÍRAT, ÉVES, APAI,
HOHÓ, FOGÓ, ÉKKŐ, ADAG, TÜLE, PICI, GYÁM, RÓKA, ERED, TÜLE, ÍVES, BÖGY, ÉVAD, DÖNG,
DUGÓ, VEJE, TÉKA, TŰZŐ, FONT, BIRS, AVAT, VIZA, BÍRÓ, KACS, GYŐZ, TYHŰ, BELE, SAKK,
RÚZS, EHUN, BAGÓ, RÜGY, ALUL, KIKI, KINŐ, ÚSZÓ, ÖCSI, EVET, SZÍJ, ÜRES, EVEZ, SZŰZ,
AGÁT, TYHŰ, SZÍJ, REDŐ, BAGÓ, ÜDÜL, NÁCI, TYHŰ, SZÉR, ELÜL, ÁNGY, MÉRV, FALÓ, PAKK,
ESTI, SÜLT, ÓZON, IRAT, ZÚZÓ, CSŐR, MÉLY, ÓZON, PONK, PELE, NAGY, CIGI, NYÁJ, RÁTA,
MINŐ, KOMI, GYŰR, VIVŐ, IVAR, LOPÓ, SŐRE, ÍREL, CSÉK, UTÁN, HŰHÓ, TUJA, TETŐ, BONG,
SEJT, ENYH, BUMM, PARI, HUJA, ÜTET, SZÖG, MARS, LEVŐ, KONG, RAGU, ESÉS, CINK, LENG,
OLÁH, ÁDÁZ, LEVŐ, ACÉL, ÁTAL, EBÉD, UGAR, FALU, FUJT, GŐTE, ÁTÜL, ELUN, EBBE, ÖCSI,
KÜNN, TOTÓ, ÁRUL, SING, MEGY, ESIK, SÜLY, BÁRÓ, ÁROK, RIZS, REST, TAVI, ELEM, PIKA,
BÚGÓ, ÚJUL, MÓKA, KÜLD, VÉSZ, ÁCSI, FIÚI, ESDŐ, DALL, LÓFŐ, DIÁK, IGEI, ALÁZ, ÜLTE,
PIRÉ, MIND, KÁDI, SZOL, PUHA, VERS, ROGY, PARI, SAVÓ, LÜKE, RANG, ARAB, OLTA, KIFŐ,
BOJT, GYÍK, ÉRIK, SÜTŐ, BUGA, CISZ, TŰZŐ, TŐKE, FASÉ, STÉG, VÉSZ, SZÁN, KACS, FÚGA,
REGE, PARI, KÁDI, ÖCSI, MINT, RÉPA, BÜKK, SING, ÜREG, PART, MOND, BUJT, CSÍP, VÍVÓ,
KIFŐ, MARI, HOLD, HÚGY, ÉTEL, BRIT, PÓKA, LAZA, LÁDD, ELÜT, ÁTOK, NYÁK, ÖKÖL, NERC,
RUGÓ, ÁRUL, ROMA, BECS, NESZ, SÜLY, ÁBRA, DÖNT, FOJT, KOPÓ, MEGY, FEJT, FUTÓ, MELÓ,
BUJT, ELÜL, DŐRE, SŐRE, TELE, JÓGA, CÁPA, KARÓ, KÖTŐ, APRÓ, ÍZÍK, MEGÉ, GŐTE, BUTI,
HUNY, ÚTŐR, VÁPA, HUHU, IGEN, SAKK, VÍVÓ, FUJT, ALUL, NYŰG, ÖRÜL, ÉVES, HANG, PONT,
ELIT, AKÁC, HUJA, HINT, VÉKA, BÓRA, RÁGÓ, BONG, PINA, KOPP, ÜHÜM, NEJE, BUTI, CIKK,
KÖZÉ, SATU, NÉMA, KÜNN, SZOP, KIRÓ, VAGY, RÁGÓ, APAD, ELŰZ, FAKÓ, ÚTŐR, ÚTŐR, HUKK,
PITE, GYŐZ, ÁLOK, CSÉP, ÚJJÁ, PÁPA, NÉPI, NYÁK, DÖNT, ÁTÍR, BÜKK, ÖLEB, SÍZŐ, BUMM,
FÚRT, FŐTE, SZÉL, HINT, LENN, PFUJ, HAZA, ÖCSI, OJTÓ, IMÁM, TÉMA, KÜNT, DUGA, MÁMI,
SZÖG, ÁMUL, SÉRT, HAJT, GYÁR, RÁNT, RIZS, ÁGAS, BARI, GYÁM, ÉTEL, ECHÓ, HERE, RONT,
LAPU, SVÁB, ÖLEB, FESS, NÉZŐ, FONT, IGEN, ÓSDI, PÁRT, BOLY, TŐGY, AKAD, ÁMUL, HANT,
VÉRT, GYÍK, GESZ, APUS, BRÓM, CSÓK, ECHÓ, BELE, RUHA, ÖLES, KEND, ÁNGY, HISZ, AVAR,
TIED, HONN, FŐTT, FIÓK, HŰHÓ, LÜKE, PÓLÓ, INAL, VEVŐ, MELY, BRÓM, ÁJER, KORA, DACI,
KONG, ELÜT, BÚGÓ, LAKÓ, PÁPÁ, POPÓ, BENT, ÜHÜM, BULI, ÍVES, PONT, CSÉP, ÁLOK, ÜRÜL,
AGÁT, SVÉD, NONÁ, FIKA, LŐRE, ALIG, MIRE, SRÉT, VEVŐ, NYÁL, BARI, TŐKE, ÁPOL, LÁTÓ,
EMEL, KONG, ROLÓ, FIÓK, BÉKÓ, NAGY, ÁPOL, SIKK, UTÓD, FINN, ÁNGY, LENG, PULI, IGÁS,
REDŐ, BÉKÓ, LEVŐ, CSÁS, RÓKA, RÓTT, NYÁR, ÁPOL, PANG, RAGU, MÓDI, FISZ, ONDÓ, KÁDI,
VÉTÓ, PEST, FOJT, FUJT, DIÁK, SZÖK, GŐTE, BARI, ESTE, SÚGÓ, MOST, ÖCSI, FRÉZ, TELE,
KÜNN, SZÁM, TÚRA, EVES, BUMM, ESŐS, ELEI, TORS, AJKÚ, HONN, MARI, SAKK, NYÁK, UTÓD,
IDÉZ, INAL, ÖRÜL, VÁLT, MOLY, KÖTŐ, ÚJÉV, BOLT, BARI, GÓRÉ, IVAR, ÁRVA, SZÁD, LENT,
TOTÓ, NANÁ, PECS, BÍRÓ, ÍGÉR, FENT, FALÓ, IPAR, BUMM, RIZS, INGA, ELÜT, VÁRT, PIKÉ,
BANK, GUGA, FEDD, BÉTA, HIVŐ, MENŐ, VÉRT, FŐTT, SEJK, ÉKÍT, PÁRT, ÖLES, PÖCS, DIÁK,
EDZŐ, SÚGÓ, FAGY, ÖREG, BAGÓ, FINN, TEVŐ, FUTÓ, TÉKA, ÚTŐR, BEÉR, VESZ, BONT, DŐRE,
ÉNEK, HÁNY, GYŰR, BÉRC, ÓKOR, VÉSZ, BUSA, HANT, HARS, CICI, DÖNT, KAPÓ, EHUN, FACH,
NYÁR, SOHA, BÖGY, AGÁT, SOKÁ, VÉNY, GYŐZ, HAGY, RÁCS, GUGA, NAGY, EBÉD, SÍZŐ, RÜGY,
SEJT, SZÍT, FÚRT, KÁKA, GYÁR, ÉGET, KÉVE, GYŐZ, REJT, ÁCSI, HANG, NYÁL, ÜRÜL, ÜRÜL,
OKOL, VEVŐ, ÜTÉR, RÁNŐ, DIKÓ, ÜDÍT, HANT, TÁTI, RIMA, KÜNT, VEVŐ, AGÁT, VÁZA, MOHA,
BULI, ÍVIK, ALUL, OJTÓ, ÁGAS, BÓDÉ, BORÚ, SZAG, SRÉG, SZŰR, RAGU, KÁPA, KEDD, BONG,
BAGÓ, CSÓK, ZÖNG, IMÁM, ÚSZÓ, KAMÓ, ECHÓ, ORSÓ, RAGU, CÁRI, ÚTŐR, MISE, KENŐ, TŰZŐ,
ECHÓ, VIVŐ, OKÍT, ÍTÉL, VONT, RÁMA, BÜKK, ALÁZ, FRÍG, ÜHÜM, MÉHE, PETE, HESS, CSÉP,
EGÉR, FAGY, BOKA, GANG, OJTÓ, PÁKA, GYÁR, ELŰZ, CSÉP, SÉMI, GÓRÉ, SZÖG, PITE, TÜLE,
VEVŐ, LAJT, IGEI, BÚGÓ, FAGY, FÓKA, BUMM, BAGÓ, ÚTŐR, FELE, IGÉZ, ZÉRÓ, EHOL, LÓFŐ,
ARGÓ, FÁMA, CUMI, IGAZ, NANÁ, ÜGET, ZÚGÓ, ÓKOR, BAKÓ, ALÍT, DONG, LINK, CSÍZ, AHOL,
SÉRT, KÁTÉ, MÉRŐ, ESTI, HUTA, MART, ELÖL, NYŰG, ZUHÉ, FUJT, UGAT, ZULU, KÁPA, CUKI,
ELÜT, BENN, FENN, ÍZÍK, BÖGY, TRIÓ, AKÁC, FŰZŐ, PÓRI, NEJE, HOGY, KÖTŐ, DOBÓ, BARI,
SÜLY, MORE, DŰNE, HALÓ, ÉKES, TÁRÓ, EMEL, ZAGY, ÉGET, BEGY, NYÁR, PONT, BÓRA, PATA,
NYÁR, PACI, LESZ, BÚGÓ, SZŐR, SZOL, KONG, TEVŐ, PIAC, FŐTE, HŰTŐ, JÁRT, TÚRA, PIPA,
SVÉD, ÚJUL, HATÓ, HANG, ELÜL, BOHÓ, ALÍT, IKER, FEDŐ, LEÁS, OJTÓ, HÉJA, MERŐ, VEND,
TEVŐ, BORS, IVÁS, DIÁK, NYÁR, NYŰG, AHOL, TŰZŐ, ZÓNA, IKES, BÁBU, MINT, TÜLL, MÉLA,
ÜRÍT, PACI, PÓRI, TŐGY, IMÁM, ELIT, ÓZON, ÚJUL, NAGY, SOLO, JEGY, POLC, KONG, ALOM,
NÉPI, ÜTÉR, KOHÓ, RUTA, SÚLY, ÜRÜL, PITE, FUJT, DACI, PEST, HÚGY, BOJT, BŐGŐ, LÍRA,
GYÍK, KEDD, DUGÓ, SÍZŐ, SEJT, FINN, DUGÓ, RENG, NÉZŐ, UGAR, DONG, ÉRIK, BŐSZ, BÖTŰ,
HAVI, MÉRT, MÉTA, HAZA, DUGA, MIRE, AJKÚ, BÖGY, BIKA, VOLT, VÉTÓ, GUGA, HŐSI, HASI,
SÍZŐ, CSÓR, TENG, ELÜL, ARAB, KÖTŐ, TART, NEJE, SZÁN, ÁTOK, SÚGÓ, ÓZON, VESZ, DÓKA,
ÖRÜL, ÜRES, SÚGÓ, ALÍT, ALÍT, TANK, KERT, PACI, PIKK, PÉTI, EHUN, LÉGI, TŐGY, DONG,
BONG, HONN, ÍRAT, SÉRT, LENN, ZAKÓ, FOJT, HÁNY, PIKK, SZOK, PSSZ, GYÍK, SZOL, PINT,
DÁDÁ, UTÓD, VÁGÓ, JÁRÓ, ÍTÉL, TRÓN, SZÚR, CICI, MOLY, EJHA, VÉKA, FOGY, SZÁZ, RÉSZ,
IKES, CISZ, EVET, BÓDÉ, LÜKE, CSŐR, DONG, JÁRÓ, BEÁS, ÉRTE, PFUJ, SÍZŐ, SEJK, PICE,
MORE, UTÓD, BUMM, EDZŐ, UTAL, AGÁR, HIVŐ, HUKK, ÚJUL, DESZ, ŐRIZ, AMAZ, SZAR, BONT,
VEND, FALÓ, HIVŐ, ÖNTŐ, VÉNY, AJAJ, VESE, VONT, RÉNY, MOLY, MÓKA, SÉMI, BEÁS, FÚGA,
ÖZÉS, SÚGÓ, LEVŐ, ÁTÉG, HŰHÓ, HŰTŐ, PÖCS, SÜLY, FÖNT, BÉKÓ, MAKK, NEJE, FAGY, KORA,
JOBB, HŰLT, TŐGY, MIRE, BEÁS, HÁGÓ, PÁRT, KINT, BUGA, KINŐ, LAJT, TANK, ZAKÓ, ÁTAL,
BÉRC, KÓRÓ, HOGY, TÖRT, NEMI, ÉKEL, ERED, ÓLÁB, LOPÓ, IGEN, FŐZŐ, SZŐR, FAIR, BÓDÉ,
FŰZŐ, OMOL, FÁJÓ, ÉGET, REMI, RÓTT, KORA, EBÉD, IGEN, ÁPOL, MARI, DŐRE, ERŐS, ÍREL,
ECHÓ, ENYH, NAPI, EZÉS, IRTÓ, ENNY, KULI, DÁDÉ, DUMA, ÁNGY, APUS, PECS, SZÉR, ÉKKŐ,
ELÖL, UGAR, RIZS, TOTÓ, FÚGA, AKÓZ, DONG, RÚGÓ, ALÁN, SÜTŐ, FACH, ÓMEN, FÚRT, TŰZŐ,
NÉHA, HÚSZ, FEDŐ, TÉNY, GYÁR, ÁTÉR, KACS, ÍRÁS, PITI, FENN, NEJE, LOPÓ, MÓDI, ÉKKŐ,
VARR, AGÁR, TŐGY, PRÍM, CSÓK, KIFŐ, ZÉRÓ, FASZ, ÖNTŐ, FRÍZ, PULI, KALL, VÉTŐ, FIÓK,
HÚGY, FÚGA, RIAN, ÉTER, LÓGÓ, SITI, KÉSZ, RONT, EVES, MONY, SETE, SZÁM, ÁGAZ, REND,
PONK, TÉKA, TOJÓ, DIRI, FÖNT, PRÉM, PAKK, LÁNG, VONT, BORÚ, FAIR, ELÍR, KÜNN, MELÓ,
GYÁR, CSÓK, HUKK, GYŐZ, TŰZŐ, FŐTE, SÍZŐ, HŰHÓ, RING, CISZ, NYÁR, ÁNGY, RAJZ, SZÓR,
RAGU, PÁPA, ÓMEN, LÓGÓ, ÁRUL, TEVE, EVES, FENT, PULT, TOJÓ, GIGA, PAPA, HIBA, EBBE,
IDEI, UTAL, SZÖK, PINT, SVÉD, SZÍT, MENŐ, PANG, ÖRÜL, ÍZÍK, RENG, VEJE, ÁGAZ, HALL
Ugyanerre a szóra egy harmadik keresésénél a futásidő 5
perc
18 mp lett, az
összes karaktersorozat száma: 64 618, az értelmes szavak száma: 821 - ezek:
SZÓR, SŰRŰ, SZŰR, ÉNEK, GAMÓ, ÁGAS, SÍVÓ, NÉGY, FIÚS, ÍJAS, BRÓM, KEND, KINN, ÚJÉV,
ÁJER, PUMI, SÍVÓ, PETE, CSÓR, ALAK, IZÉL, PÁPÁ, FÓKA, ANNO, ZÁRT, EVEZ, HÍVÓ, BETŰ,
FASÉ, FŰTŐ, BÉKA, IGÉZ, HOHÓ, LÜKE, LÁNY, KANI, TÁRT, FENN, IVÁS, KELL, DÁMA, TERÜ,
GNÓM, GESZ, NEDV, TÉMA, ÜTEG, SZÉL, MÁRC, ÁMUL, DÁMA, SEGG, ÜHÜM, BEGY, ÁGÁL, EVET,
RÜGY, BÚZA, SZŰR, NEDV, DUGÓ, TELŐ, NEKI, NÉNI, ZAGY, DARA, ÉHEN, SICC, RÁZÓ, CSÖG,
HÍVÓ, SÍVÓ, HÍJA, FISZ, ÁRUS, VICI, ÖLTŐ, PFUJ, VICI, ROGY, ÍREL, ÖRÜL, APUS, ROLÓ,
CSÍN, TETT, EJHA, ÖLTŐ, NÉHA, ÓVÁR, KÖTŐ, DÁDÁ, RÚZS, MERŐ, TENG, ÉRTE, ÁTAL, ÉNEK,
ALUL, PÓLÓ, BAGÓ, ÍZÉS, ÁTÉR, HANG, VIZA, MÁRT, GYŰR, BUSZ, SVÉD, CSŐR, FIÚS, BUSA,
FUJT, HÍVÓ, FÖLD, IGÉZ, TÚSZ, LÁNG, PÖCS, TOPA, VÍVÓ, RÁNŐ, FUTÓ, KIFŐ, ÖNTŐ, VELE,
FÖNN, KÉVE, ALVÓ, ZUHÉ, ÓBOR, RÁCS, TERÜ, AMÍG, TERÜ, LÉHA, TUJA, ZAGY, PÖCS, KORC,
HUJA, FENT, LŐRE, ALOM, DICS, ELŐZ, SZŰR, ÜTET, IDŐS, LAPU, KAPA, ELŐL, KŐSÓ, BŐSZ,
REJT, TÁRÓ, MOLL, TERÜ, ÁLOM, BEGY, PASA, TELI, BURA, TOKA, SÜTŐ, TÚSZ, SZÁK, PULI,
APAI, ZSÚP, RÁCS, ALAP, PONC, KOMA, URAZ, FŰTŐ, RÁGÓ, RÉSZ, HÓLÉ, LŐRE, ÖLTŐ, GYÍK,
PAPA, ZACI, JUSS, HUNY, DONG, FASZ, VETŐ, SÍRÍ, BÉTA, ÉLÉS, LÍRA, MOHA, ALLÉ, ELVI,
SÍVÓ, FUJT, BEGY, VÍVÓ, PÁST, VÁLL, BÓRA, ÁTAL, HISZ, VESZ, GYŰR, ÜHÜM, EMEL, TEKE,
SÚJT, RANG, SZÉP, UTÁN, UTÁN, ÚTŐR, PACI, LŐTT, BABA, ÓRAI, IDŐS, CSÉR, JOBB, TERV,
KULI, ÉHES, HAGY, BÍRÓ, ÚJON, SZÉT, KERT, EMEL, DOBÓ, AJTÓ, FŐTE, HOHÓ, NAPI, DALL,
IDUS, LAMÉ, NÉZŐ, SZÁZ, KÖZÉ, SOSE, ÜRÜL, BÖGY, TEKE, BÚGÓ, PACI, MÉRT, CSÚF, SŰRŰ,
ÖVÉK, ÉTEK, BŐGŐ, EVÉS, ÉNEK, SAVÓ, DICS, PÓRI, ÁTAD, SÜLT, CETT, GYŰR, NAGY, MEGY,
HASÉ, MÉRT, PINA, TŐGY, AKÁC, TILÓ, FÁTA, POPÓ, MINT, HAJÓ, SÍVÓ, HUTA, HÍVÓ, ESŐS,
BOHÓ, SŰRŰ, ÜLET, BULI, TUDÓ, SZÉT, KULI, TOKA, HAMM, FŰZŐ, IGEI, FIÓK, OSON, ÁCSI,
UGOR, ELÖL, MAGA, ESŐS, VÍVÓ, IDEG, FENE, NYIT, GUMI, ÍGÉR, AKÁR, ÓBOR, ELUN, BELE,
ASZÚ, ASZÚ, GŐTE, ÓVÁR, REND, ELŐL, ÁMUL, ÜLÉS, ELUN, UTAS, ÖVÉK, FIÚI, REDŐ, HOZÓ,
JAJA, ELŐZ, ÍVÁS, GYŰR, AKÁR, PFUJ, KÚSZ, LÉGI, LELŐ, GNÓM, CSEL, ZÚZA, SÉMA, SZÁR,
IDŐS, VIVŐ, MAKI, PÁST, ZSÚP, ÁMÍT, FOTÓ, ŐRÖL, ZACI, GYŐZ, ÜRÜL, TETŰ, SZAB, CSEN,
APAI, NEDV, PINT, KÚSZ, VAJH, KAMÓ, VÁGÓ, IKER, TAVI, KOHÓ, SŰRŰ, ÓNAS, ÚTŐR, SURC,
DEÁK, SOKÁ, NYÍR, RAGU, EGÉR, LŐTT, MEZŐ, ÁTÍR, VOLT, ILLÓ, KÜNT, FÁMA, FÜGE, BELŐ,
FENN, ÍGÉR, ALLÉ, AJAK, HIÚZ, KÁBA, VÉKA, VÉTŐ, FŰTŐ, KÜLD, NONO, LŐTT, TÁRT, ÚZUS,
HASÉ, HŰHÓ, SÍRÓ, ÁCSI, HŰTŐ, VÁPA, COPF, KAMÓ, GYŰR, SEJT, RÉNY, POPÓ, MENT, ÖVÉK,
DOBÓ, PELE, OJJÉ, SZÉR, ELŐZ, PART, FŰTŐ, ASZÚ, ESŐS, MOHA, BŐSZ, TAHÓ, ÉKEL, VÉRT,
SÍVÓ, TÚRA, ÉLED, MELL, PÓRI, GYŰR, IKER, BENŐ, ÉTER, DUGA, PIPA, KÉNY, RÖMI, APAD,
BOKA, ÁMEN, SÍVÓ, ALVÓ, HOHÓ, SZŰR, PÖCS, LÜKE, TILT, ÚJUL, ÍREZ, TETŰ, KINŐ, SÍRÍ,
ÍJAS, ÁCSI, PINA, ALVÓ, DAKU, JEGY, GYŰR, HONN, NIPP, ÓBOR, ÁRAM, DÁMA, FUGA, BÓRA,
LÁGY, BRIT, KUSS, ABBA, AKOL, DUGA, ABBA, DŐLT, FÉNY, PICI, HETI, RÁGÓ, EMEL, ÁJUL,
EPED, NÉMA, RÜGY, UGOR, SZÉL, ZSÁK, HUSS, ZÚZA, PFUJ, PIHA, TÓRA, CSAL, AKUT, RÉSZ,
TÚLI, SÁNC, PIKÉ, SZŰR, RÁGÓ, ÉTER, DÓKA, SÜTŐ, GUMÓ, LŐRE, DELI, SÍVÓ, LAMÉ, SZŰR,
CSEN, ALLÉ, DALL, ICCE, GYŰR, GNÓM, SŰRŰ, LAMÉ, ÉLET, KIÚT, CSÉR, ÖNTŐ, SZÓR, HÚGY,
OLLÓ, HERE, UTÁN, MENT, LÁMA, MENY, ODOR, FŰZŐ, TŐLE, LILE, VÁRT, ZSÚR, HEHE, HÚGY,
PÁVA, NÉMI, ÁLDÓ, NAPI, TABU, ESET, KÁPA, MÉTA, CSÉR, MOLL, VÉLT, VAJH, PALI, ÚTŐR,
PORC, VAGY, SZŰR, ÜLTE, CICA, HÚGY, GYŰR, SUNY, MOHA, BÚZA, ÜREG, ASZÚ, VÁLU, CIPÓ,
KORA, GYÍK, CSÚZ, ÁBRA, TŐLE, PÖCS, FŰTŐ, OSON, TÁRT, ÖRÜL, VICC, CÁRI, DŐLŐ, RÁCS,
SZÁZ, ASZÚ, VÁRÓ, BIGE, ÁGAZ, DERŰ, ÉGER, KAPU, BÚGÓ, ALAK, SÜLT, BÉKE, ZACI, HULL,
EMEZ, ALIG, SZÉP, FÓKA, LETT, NYIT, DICS, GYŰR, DACI, ERED, ÜGET, CSÉP, PÓNI, AISZ,
LEPE, SŰRŰ, IDOM, ÓNIX, IMÁD, BEÍR, MOHÓ, ÜRÖM, FOLT, KÖZÉ, PART, NYAK, SOTU, ELEI,
KIÚT, TŐLE, FEDŐ, ÚJUL, ÉKEL, PÖCS, TELT, PACI, ELŐL, GYŰR, ÓNOZ, CSŰR, UTÁL, REGE,
CSÚZ, ZACI, BÉKE, ÁRUL, SZAG, PITE, PÓLÓ, SZÉT, AKÁR, UKÁZ, ASZÚ, DÓKA, ÜREG, ALÉL,
RÜGY, UGOR, SÉMA, AJKÚ, SZÉL, FŐZŐ, RÜGY, PITI, ELŐL, SÉRV, VESE, KŐSÓ, MIND, TINÓ,
SZÉK, ÁCSI, PUHA, APUS, ÖLFA, LÉGY, ÉLEZ, FISZ, ÉVES, BUDI, ÚZUS, LILE, SÉRV, EMEL,
DERŰ, BUJA, NYAK, SAVÓ, PULI, DICS, TŐKE, KAMÓ, NYÍR, ELÁS, KOMA, BÉKE, SÚJT, KŐSÓ,
SÍVÓ, BEÁS, LETT, NYÍR, PÖCS, ILLŐ, RÁRÓ, SŐRE, SZÉL, LŐRE, TAPP, GÖCS, RÓTT, RÓTT,
LÁMA, PÖNG, KÁPA, APÓS, HAGY, ÜREG, GYÍK, RÉNY, SZÚR, SEJK, PIKÉ, SÍVÓ, BÉNA, MÉRT,
EMEL, EPÉS, ÓLOM, FÜGE, BŐSZ, DEKA, LEÍR, OROZ, SÍVÓ, GÖCS, PITI, ÜRÖM, HAGY, MÉCS,
RELÉ, RÁZÓ, TŰZŐ, FŰTŐ, VIVŐ, SZÉN, KÖTŐ, ÖVEZ, AKTA, ÁGÁL, ÚTŐR, TÖRŐ, VÁZA, GŐTE,
ILLÓ, ZAGY, ZAGY, TATA, HŰTŐ, SZŰR, MUST, OLTÓ, FÉLŐ, KOMA, HÚGY, NÉNE, ÜTEG, AKTA,
GRÍZ, BEÍR, ÜVEG, ALVÓ, DICS, TÖLT, SZÓL, NÉZŐ, ÉREZ, KÁBA, RÉPA, CETT, EPED, URAS,
NEDV, TÁCA, VISZ, EPER, ICCE, NOHA, SOTU, GYŰR, BURA, ASZÚ, NYÍR, ÁTOK, GYÍK, SÜLY,
HÍJA, OBOA, SICC, BUKÉ, ÚTŐR, NYÍR, SÜTŐ, ZULU, CICI, DOBÓ, MENY, PIKÉ, GYÍK, ÉDEN,
SÍVÓ, IDÉZ, VAJH, HOHÓ, NYÍR, LEPE, ÉHEN, ÚJUL, ALÓL, DACI, ALVÓ, HÚSZ, APUS, KINŐ,
BÓLÉ, MOHÓ, SZÚR, ALVÓ, HÁGÓ, GYŰR, FEKÜ, KÖZÉ, HALL
 Egy majom ül egy
írógép előtt. Az írógépen csak nagybetűk és egy sorváltó billenytű
van. A majom egymás után nyomkodja az írógépen az ábécé betűt, majd időnként új sort
kezd.
Természetesen
teljesen
értelmetlen betűsorozatokat ír le egymás után.
Egy majom ül egy
írógép előtt. Az írógépen csak nagybetűk és egy sorváltó billenytű
van. A majom egymás után nyomkodja az írógépen az ábécé betűt, majd időnként új sort
kezd.
Természetesen
teljesen
értelmetlen betűsorozatokat ír le egymás után.
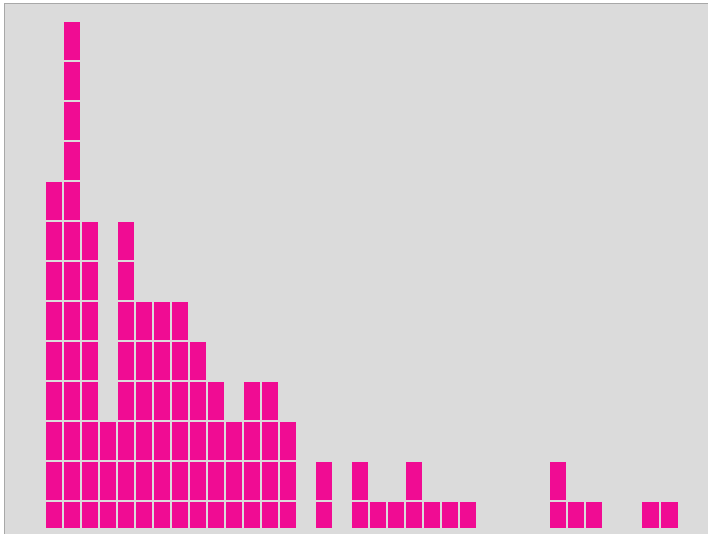


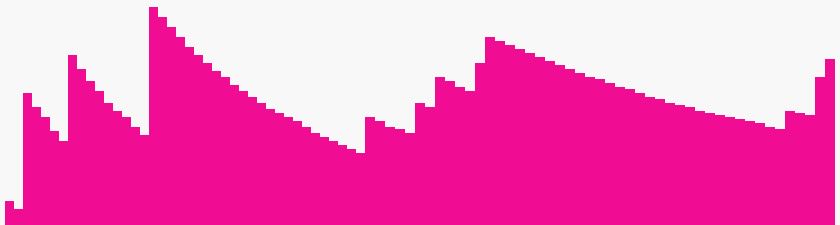
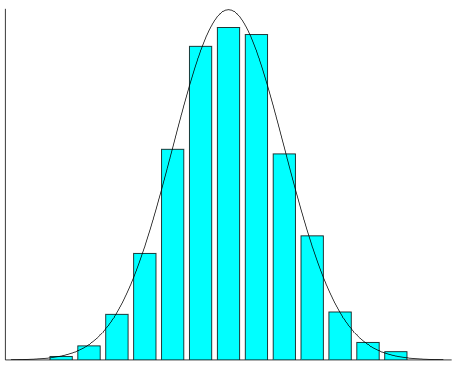 Vegyük egy népcsoport tagjainak a magasságát. A legtöbb ember közülük átlagos
magassággal
fog
rendelkezni. Az ő számukat jelzi a legmagasabb - a középső - oszlop. Az
átlagnál 10
cm-rel
magasabb vagy 10 cm-rel alacsonyabb emberek kevesebben
vannak. Ez a két oszlop lesz a legmagasabb oszlop két közvetlen szomszédja. Ez a
két
szomszédos oszlop
értelemszerűen alacsonyabb, de egymással - várhatóan - azonos magasságúak. (
Vegyük egy népcsoport tagjainak a magasságát. A legtöbb ember közülük átlagos
magassággal
fog
rendelkezni. Az ő számukat jelzi a legmagasabb - a középső - oszlop. Az
átlagnál 10
cm-rel
magasabb vagy 10 cm-rel alacsonyabb emberek kevesebben
vannak. Ez a két oszlop lesz a legmagasabb oszlop két közvetlen szomszédja. Ez a
két
szomszédos oszlop
értelemszerűen alacsonyabb, de egymással - várhatóan - azonos magasságúak. (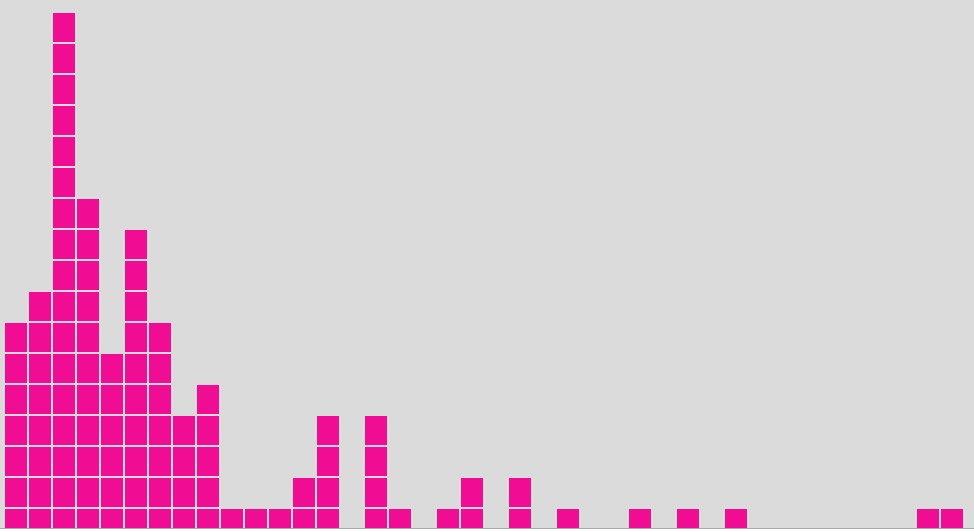 Az oszlopgrafikonra pillantva azonnal szembetűnik, hogy itt nem egy Gauss
eloszlásról van
szó,
amelynek a maximuma a 9-nél van. Itt az oszlopok magassága rendre: 7, 8, 17, 11, 6,
10, 7,
4, 5, 1, 1, 1, 2, 4, 0, 4, 1, 0, 1, 2, 0, 2, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0,
0, 0, 0,
1, 1.
Az oszlopgrafikonra pillantva azonnal szembetűnik, hogy itt nem egy Gauss
eloszlásról van
szó,
amelynek a maximuma a 9-nél van. Itt az oszlopok magassága rendre: 7, 8, 17, 11, 6,
10, 7,
4, 5, 1, 1, 1, 2, 4, 0, 4, 1, 0, 1, 2, 0, 2, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0,
0, 0, 0,
1, 1.

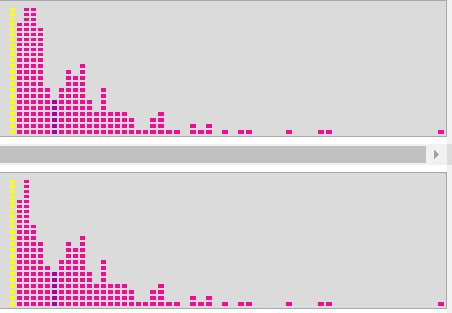
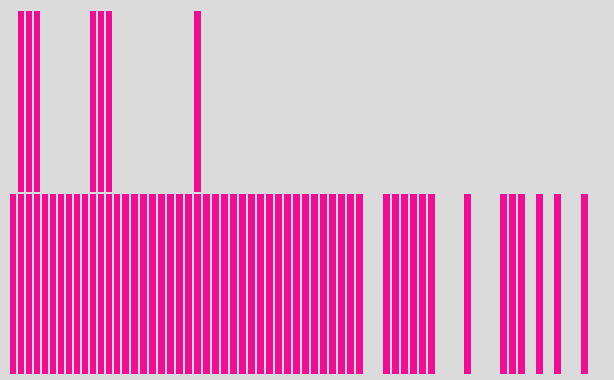
 Ezt mutatja meg a következő
képpár.
Most
500-szor
futtatuk le egymás után 'a majom kétbetűs szavakat keres 500-szor
beállítással a
programot, s kaptunk 500 - 500 eredeti és konstruált eloszlást. Mindkét
eloszláscsoportban
vettük
az egyes oszlopok átlagértékét, s itt láthatjuk ezt a két
'átlageloszlást'.
Észre lehet
venni,
hogy a két oszlopgrafikon alig tér el egymástól. Így akár még az is
lehetséges,
hogy a
'természet' hasonlóan kontruálja meg az eloszlást, ahogy mi is tettük.
Ezt mutatja meg a következő
képpár.
Most
500-szor
futtatuk le egymás után 'a majom kétbetűs szavakat keres 500-szor
beállítással a
programot, s kaptunk 500 - 500 eredeti és konstruált eloszlást. Mindkét
eloszláscsoportban
vettük
az egyes oszlopok átlagértékét, s itt láthatjuk ezt a két
'átlageloszlást'.
Észre lehet
venni,
hogy a két oszlopgrafikon alig tér el egymástól. Így akár még az is
lehetséges,
hogy a
'természet' hasonlóan kontruálja meg az eloszlást, ahogy mi is tettük.
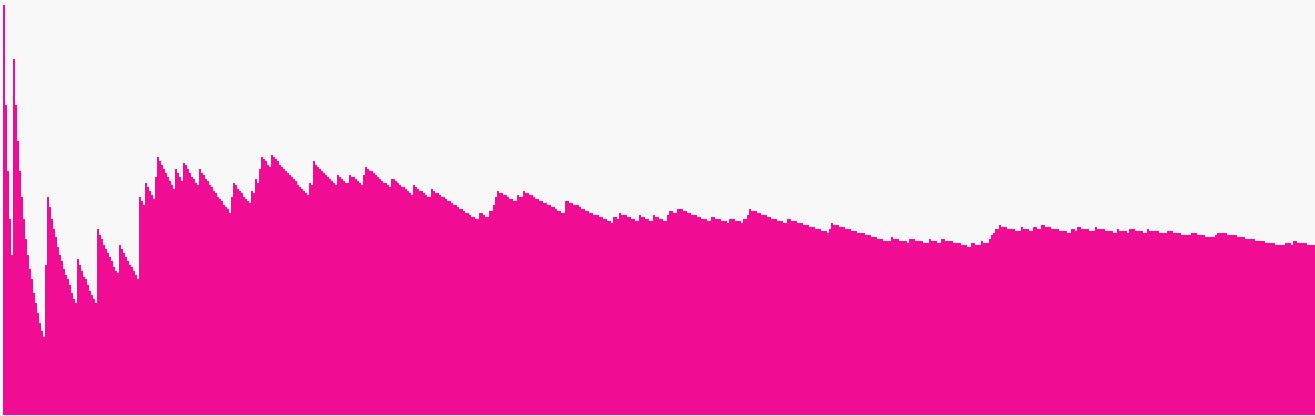
 A kép egy 'a majom négy betűs
szavakat keres
100-szor' kereséssorozat ürességeloszlását mutatja. Láthatjuk,
hogy az
ürességek hosszát jelképező oszlopok magasságának a növekedése egy
exponenciális
trendet mutat. Az oszlopok lassan kezdenek növekedni, majd hirtelen a
vége felé
extrém módon megnőnek. A képen az utolsó oszlopok magasságai: 9, 90, 38,
121,
54, 6, 7, 265, 15, 59, 327.
A kép egy 'a majom négy betűs
szavakat keres
100-szor' kereséssorozat ürességeloszlását mutatja. Láthatjuk,
hogy az
ürességek hosszát jelképező oszlopok magasságának a növekedése egy
exponenciális
trendet mutat. Az oszlopok lassan kezdenek növekedni, majd hirtelen a
vége felé
extrém módon megnőnek. A képen az utolsó oszlopok magasságai: 9, 90, 38,
121,
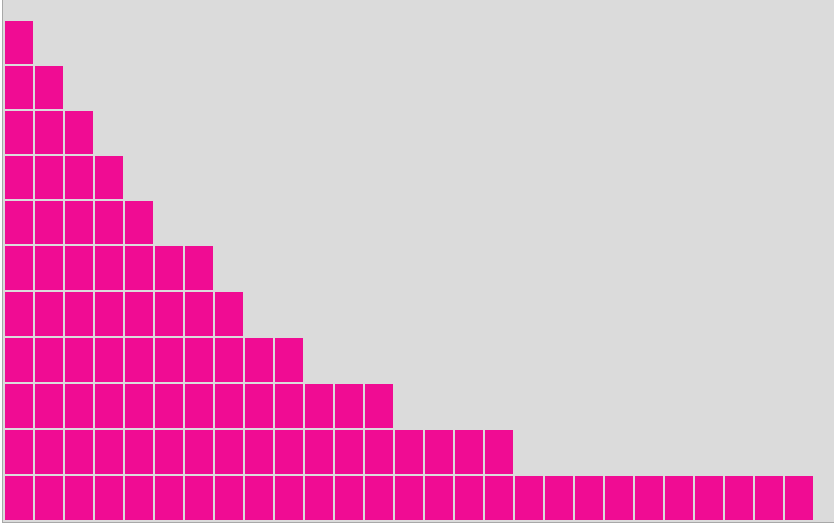
54, 6, 7, 265, 15, 59, 327.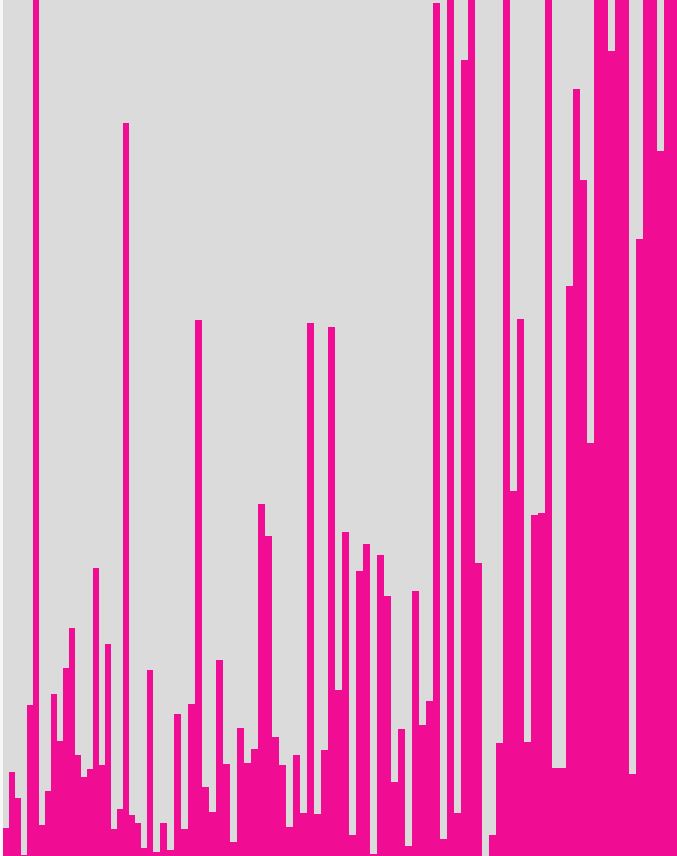 A következő 'a majom öt
betűs
szavakat keres
100-szor' ürességeloszlása.
A következő 'a majom öt
betűs
szavakat keres
100-szor' ürességeloszlása. „Az univerzumot (amelyet mások Könyvtárnak neveznek) meghatározatlan és talán végtelen
számú, hatszög alakú galéria alkotja, melyeknek közepén alacsony korláttal körülvett nagy
szellőzőaknák vannak. Minden hatszögből láthatók lefelé és felfelé az emeletek – sehol sincs
végük. A galériák beosztása egyforma. Kettőt kivéve minden oldalon öt – összesen húsz –
hosszú polc takarja a falakat a földtől a mennyezetig … minden polcon harminckét azonos
nagyságú könyv, minden könyv négyszáztíz oldalas, minden oldalon negyven sor, minden sorban
mintegy nyolcvan fekete betű. … az ortográfiai jelek száma huszonöt … szinte valamennyi
könyv kaotikus zagyvaság. … egy értelmes sor vagy egy pontos hír körül mérföld hosszúságú
esztelen kakofónia, verbális limlom és összefüggéstelenség található.” (Kép: Érik Desmazièr
- Bábeli könyvtár -
„Az univerzumot (amelyet mások Könyvtárnak neveznek) meghatározatlan és talán végtelen
számú, hatszög alakú galéria alkotja, melyeknek közepén alacsony korláttal körülvett nagy
szellőzőaknák vannak. Minden hatszögből láthatók lefelé és felfelé az emeletek – sehol sincs
végük. A galériák beosztása egyforma. Kettőt kivéve minden oldalon öt – összesen húsz –
hosszú polc takarja a falakat a földtől a mennyezetig … minden polcon harminckét azonos
nagyságú könyv, minden könyv négyszáztíz oldalas, minden oldalon negyven sor, minden sorban
mintegy nyolcvan fekete betű. … az ortográfiai jelek száma huszonöt … szinte valamennyi
könyv kaotikus zagyvaság. … egy értelmes sor vagy egy pontos hír körül mérföld hosszúságú
esztelen kakofónia, verbális limlom és összefüggéstelenség található.” (Kép: Érik Desmazièr
- Bábeli könyvtár -  Az emberi test összes információja a DNS-ben van kódolva. A DNS-ben a
hélix - a kettrős spirál - létrafokain négy nukleotid ismétlődhet párban. Ezek: az
adenin, a timin, a guanin és a
citozin.
Az emberi test összes információja a DNS-ben van kódolva. A DNS-ben a
hélix - a kettrős spirál - létrafokain négy nukleotid ismétlődhet párban. Ezek: az
adenin, a timin, a guanin és a
citozin.
 Ha akarja,
akkor a program most
lefuttat -szor egy
betűszámú keresést úgy, hogy minden
.
futás végén
megvizsgálja, hogy mennyivel nőtt meg a tanulás során feljegyzett
betűkettősök
száma.
Ha akarja,
akkor a program most
lefuttat -szor egy
betűszámú keresést úgy, hogy minden
.
futás végén
megvizsgálja, hogy mennyivel nőtt meg a tanulás során feljegyzett
betűkettősök
száma.